 von
von Was ist „Invariante Objekterkennung“?
Menschen haben die Fähigkeit, visuelle Objekte schnell und zuverlässig zu erkennen, unabhängig vom Blickwinkel oder der Entfernung, aus der das Objekt betrachtet wird. Für Computer hingegen war diese Aufgabe lange Zeit eine Herausforderung. Mit Methoden der Muster-Erkennung können zwar Bilder wiedererkannt werden. Aber wenn sich ein Objekt dreht oder aus einer anderen Entfernung betrachtet wird, erzeugt es auf der Netzhaut (oder in einem Kamera-Chip) ein völlig anderes Muster von Bildpunkten („Pixeln“). Die Fähigkeit, Objekte auch bei Variation von Blickwinkel, Entfernung oder Beleuchtungs-Bedingungen robust wiederzuerkennen, nennt man „Invariante Objekterkennung“.
Zeitliche Korrelationen als Hinweis auf Zusammengehörigkeit
Wenn wir uns bewegen, während wir ein Objekt betrachten, sehen wir nacheinander – also zeitlich korreliert – verschiedene Ansichten dieses Objekts. Diese Korrelationen zum Lernen invarianter Objektrepräsentationen zu nutzen, ist die Grundidee meines Aufsatzes „Using Spatiotemporal Correlations to Learn Topographic Maps for Invariant Object Recognition“ [Michler, Eckhorn und Wachtler in ‚Journal of Neurophysiology‘ (2009)].
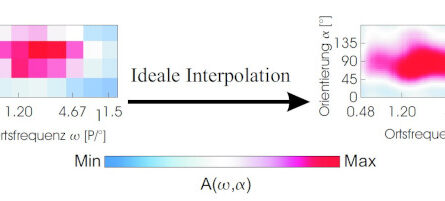
In dem von mir vorgeschlagenen künstlichen neuronalen Netzwerk-Modell werden selbstorganisierende neuronale Karten gelernt, deren Nachbarschafts-Beziehungen sowohl von Ähnlichkeit („räumliche Korrelationen“) als auch von der zeitlichen Abfolge („zeitliche Korrelationen“) während des Lernprozesses beeinflusst werden.
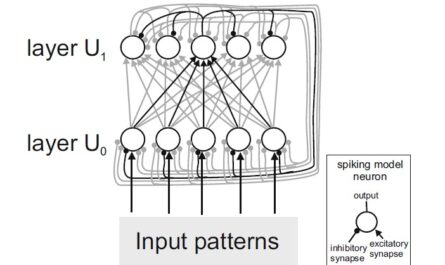
Netzwerkmodell mit drei Schichten
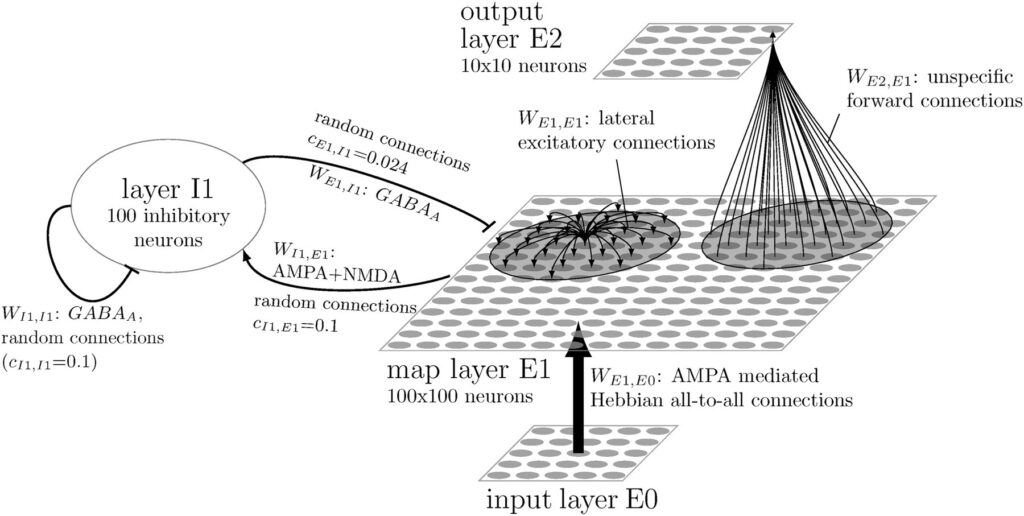
Das Netzwerkmodell besteht aus drei Schichten künstlicher Nervenzellen („Neuronen“): E0, E1 und E2. In der Input-Schicht E0 werden die zu erkennenden Bilder als Pixel-Muster eingespeist, wobei die Helligkeit eines Pixels auf die Aktivität eines Neurons übertragen wird. In der Karten-Schicht E1 werden Muster-Detektoren gelernt. Durch laterale Inhibition (vermittelt über eine Schicht inhibitorischer Neuronen I1) wird verhindert, dass alle Neuronen in E1 gleichzeitig aktiv sind: Die am stärksten aktivierten Neuronen aktivieren die inhibitorischen Neuronen, welche die Aktivität der übrigen Neuronen in E1 unterdrücken. Dies bewirkt eine Art Konkurrenz zwischen den Neuronen in E1 und ermöglicht, dass sich beim Lernen unterschiedliche Muster-Detektoren herausbilden. Die kurzreichweitigen erregenden (excitatorischen) lateralen Verbindungen zwischen den E1-Neuronen bewirken, dass benachbarte Neuronen ähnliche oder häufig zeitlich aufeinanderfolgende Input-Muster lernen. Dadurch bilden sich neuronale Karten heraus, welche zeitliche und räumliche Korrelationen der gelernten Stimuli widerspiegeln.
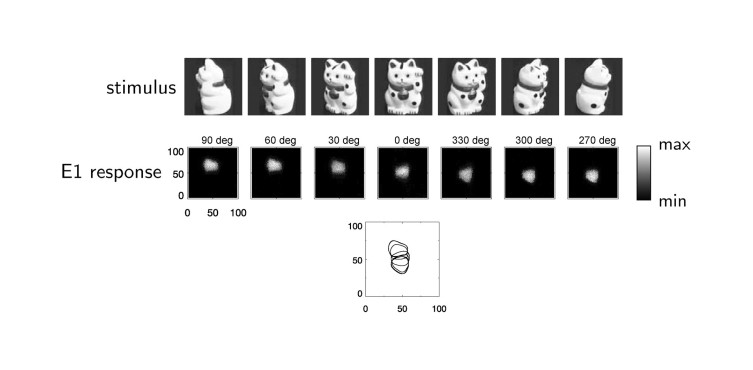
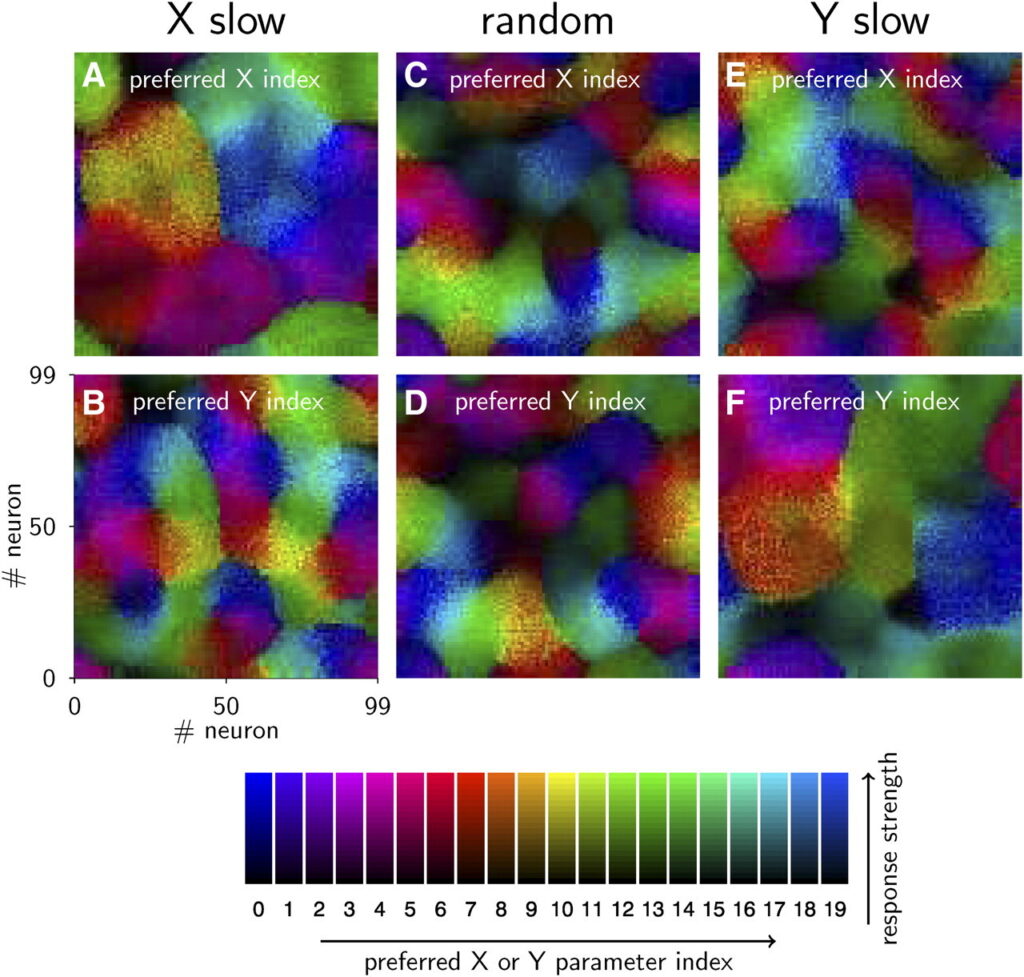
Die in den Abbildungen 4 (siehe oben) und 5 der Arbeit gezeigten Ergebnisse demonstrieren, dass das vorgeschlagene Netzwerkmodell dazu in der Lage ist, invariante Objektrepräsentationen auf Basis zeitlicher Korrelationen zu lernen.
Biologie-nahe „impulskodierende Neuronen“
Die einzelnen Schichten des Netzwerkmodells bestehen aus „impulscodierenden“ (oder auch „spikenden“) Modellneuronen. D.h., analog zu biologischen Neuronen wird der Zeitpunkt einzelner „Aktionspotentiale“ simuliert. Andere Arten von Netzwerkmodellen wie z.B. „convolutional neural networks“ (CNNs) oder Transformer-Modelle benutzen hingegen Modellneuronen, welche lediglich die durchschnittliche Feuerrate der einzelnen Neuronen berücksichtigen. Mit diesen Netzwerkmodellen wurden in den letzten Jahren enorme Fortschritte erzielt: sowohl bei der Objekterkennung als auch in anderen Bereichen wie Spracherkennung und Text-Vervollständigung. Und diese Fortschritte waren möglich, obwohl (oder weil?) die Netzwerke auf wesentlich vereinfachten Modellneuronen basieren. Allerdings stoßen diese Modelle mittlerweise an technische Grenzen bezüglich der verfügbaren Hardware und dem Energieverbrauch.
Da bei Netzwerken mit „impulscodierenden“ Modellneuronen pro Zeitschritt jeweils nur ein kleiner Teil der Neuronen Aktionspotentiale generiert, muss wesentlich weniger Information an andere Neuronen weitergeleitet werden. Bei Nutzung neuromorpher Hardware besteht hier daher die Chance auf deutliche Effizienzgewinne. Daher ist es weiterhin sinnvoll, auch Netzwerkmodelle mit „spikenden“ Modellneuronen zu erforschen (siehe S. 59 in Abschnitt 4.7 meiner Doktorarbeit).